Vue générale de Kafka
2020-05-31 par Badre BSAILA
Kafka est une implémentation du célèbre patron de conception publish-subscribe. Il permet à deux composants de communiquer avec un modèle événementiel. Kafka possède plusieurs points forts : performant, distribué (pouvant même couvrir plusieurs régions-cloud), scalable et tolérant aux pannes. Je vais essayer de se focaliser sur l’architecture technique plutôt que les librairies clientes (peut être que je vais prévoir un autre billet pour ça) et comment elle lui confère les propriétés précédentes. Bonne lecture !
Système de messagerie
-
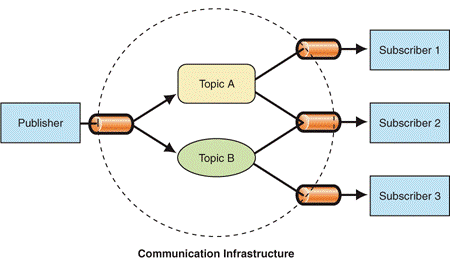
Un système de messagerie est une implémentation du patron de conception publish-subscribe :
-
Des composants appelés consommateurs peuvent souscrire pour recevoir des messages particuliers sans connaître leurs sources.
-
Des composants appelés producteurs peuvent créer des messages particuliers sans se soucier de qui va les consommer.
-
-
Avantages:
-
Faible couplage: les consommateurs et les producteurs n’ont pas connaissance de leur existence mutuelle, du coup ils peuvent évoluer indépendamment les uns des autres.
-
Scalabilité: on peut multiplier les producteurs et les consommateurs de façon dynamique en période de montée en charge.
-
-
Exemples: Kafka, RabbitMQ, Apache ActiveMQ (HornetQ),…
C’est quoi Kafka ?
-
Un système de messagerie distribué:
-
Il permet de publier et consommer un flux de messages.
-
Stocke le flux de messages avec tolérance aux pannes.
-
Traite le flux de messages d’une façon séquentielle.
-
-
2 use-case pour Kafka:
-
Développement de systèmes de streaming de messages entre différents composants.
-
Développement de systèmes de streaming qui recomposent les flux de messages.
-
-
Kafka est déployé sur un cluster de plusieurs serveurs qui peuvent être localisés sur des datacenter éloignés.
-
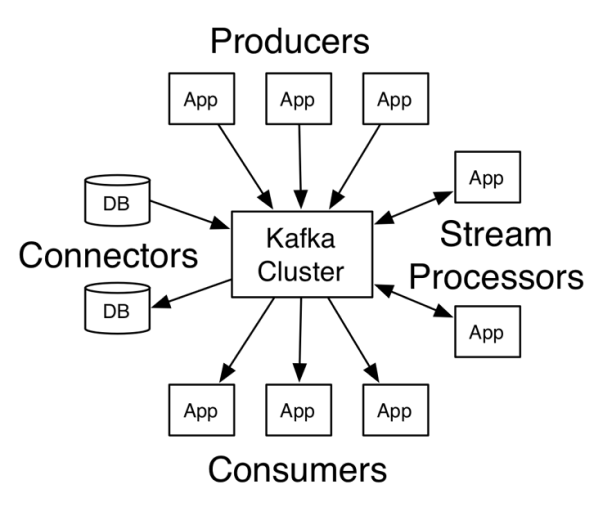
Kafka possède 4 API:
-
Producer API pour publier des messages sur les topic.
-
Consumer API pour souscrire à un ou plusieurs topic et lire depuis un flux de messages.
-
Streams API qui permet de lire un ou plusieurs flux de plusieurs topic, les transformer, et les republier par la suite sur d’autres topic.
-
Connector API afin de connecter les topic Kafka aux applications existantes et bases de données. Par exemple: un connecteur sur une BD peut capturer chaque nouvelle ligne insérée pour publier un message.
-
Topic et partition
-
Un topic est un compartiment logique nommé sur lequel seront publiés les messages et depuis lequel on peut les consommer.
-
Un topic peut avoir plusieurs producteurs/consommateurs.
-
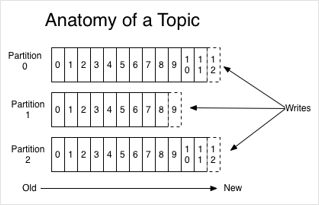
Chaque cluster Kafka maintient plusieurs partitions d’un même topic. Une partition est un réplica immutable et ordonné séquentiellement avec des messages.
-
Un message consiste en une (clé + valeur + timestamp) et possède une position sur la partition nommée offset.
-
Le serveur Kafka persiste les messages de façon durable avec une période de rétention pré-configurable, un message consommé reste dans le cluster tant que la période de rétention ne s’est pas écoulée.
-
Kafka réplique plusieurs partitions d’un même topic pour :
-
Scaler un topic au-delà de la capacité de stockage d’un seul serveur: une partition doit être stockable dans un seul serveur du cluster Kafka.
-
Tolérer aux pannes des serveurs sans perte de messages.
-
Paralléliser les lectures de messages d’un même topic par plusieurs consommateurs.
-
Consommateurs et producteurs
-
Un producteur publie des messages sur des topic. Le producteur est responsable de choisir quel message à assigner à quel partition du topic. Ça peut être implémenté avec un algorithme round-robin pour équilibrer la charge ou en s’appuyant sur la clé du message.
-
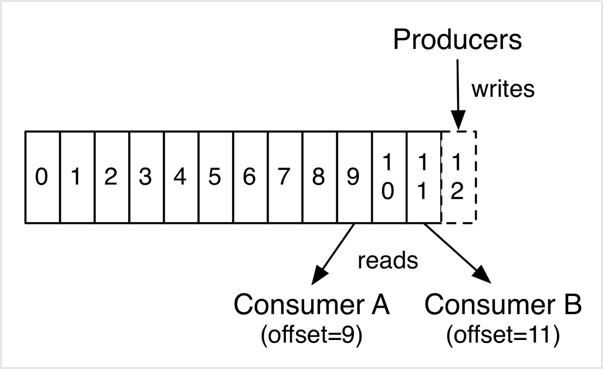
Un consommateur lit des messages des topic. La seule donnée qu’utilise Kafka pour tracker les consommateurs est l’offset du message suivant à lire dans la partition du topic consommé, à noter que l’offset initial est fixé par le consommateur qui peut choisir de commencer par le premier, le dernier, ou le n-offset.
-
Quand un consommateur lit un message du topic, son offset est déplacé vers celui du message suivant.
-
Le fait que Kafka suit juste les offset, rend la charge des consommateurs négligeable sur le cluster Kafka.
-
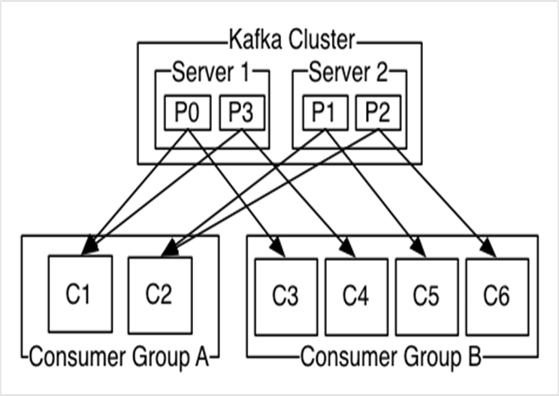
Un consommateur appartient à un groupe de consommateurs (consumer group), chaque message publié dans un topic est lit par un seul consommateur du consumer group:
-
Les consommateurs d’un même consumer group peuvent souscrire à plusieurs topic.
-
Si tous les consommateurs appartiennent à un même groupe, les messages par topic seront load-balancés entre ces derniers.
-
Si des consommateurs existent sur différents groupes, ils recevront tous les mêmes messages.
-
-
Kafka divise les partitions de façon équitable entre les consommateurs:
-
Si de nouveaux consommateurs rejoignent un groupe, ils vont retenir un peu des partitions des autres.
-
Si des consommateurs dégagent, les partitions libérées seront distribuées sur les restants.
-
Distribution et Géolocalisation
-
Les partitions sont distribuées sur les serveurs du cluster Kafka. Chaque serveur s’occupe d’une partie des données et requêtes pour une partie des partitions. Le facteur de réplication des partitions est configurable et permet de tolérer aux pannes qui peuvent toucher une partie des serveurs.
-
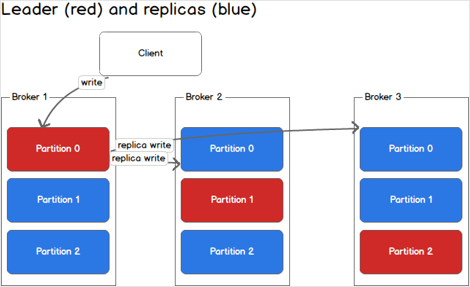
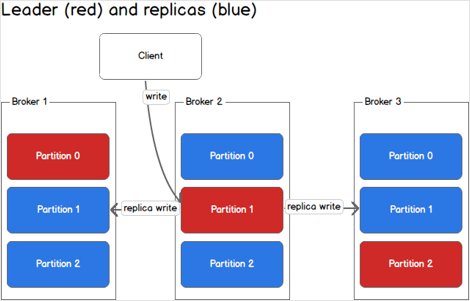
Chaque partition possède un serveur leader et 0 ou plusieurs autres serveurs follower:
-
Le leader gère toutes les opérations de lecture-écriture.
-
Les follower ne font que répliquer le leader passivement.
-
-
Quand un leader est en panne il devient follower et un nouveau leader est élu parmi les autres follower.
-
Chaque serveur du cluster se comporte comme leader pour certaines partitions et follower sur les autres, ce qui permet d’équilibrer la charge entre ces derniers.
-
Le process d’élection des leaders des partitions est très critique, pour cela le cluster Kafka utilise Zookeeper et définit un serveur comme étant controller ou leader. Ce dernier est responsable de détecter les pannes au niveau de tous les serveurs du cluster Kafka et changer les leaders des partitions en conséquence. Si le controller tombe en panne un nouveau est élu parmi ceux survivants.
-
La géo-réplication est supportée via Kafka MirrorMaker: les messages sont répliqués à travers plusieurs datacenter ou régions-cloud. On peut implémenter des use-case de backup et recouvrement, et même placer certaines données plus proches de certains utilisateurs.
Gestion du stockage
- Kafka utilise le système de fichier pour stocker et cacher les messages. Généralement on croit que les accès disque sont absolument lents par rapport à ceux de la mémoire RAM. Dans la figure une comparaison du nombre d’entiers par second qu’on peut lire depuis un fichier de 4 GB: tant qu’on fait des accès séquentiels on est cool
 .
.

-
Les systèmes de messagerie utilise en général des arbres binaires pour le stockage des données et des métadonnées sur les consommateurs. Sachant que la complexité des opérations sur les arbres binaires est O(log N) et les accès arbitraires sur disques ne sont pas parallélisables, les performances finissent par devenir super-linéaires.
-
Kafka repense le lecture/écriture des messages comme la lecture/écriture séquentielle sur un fichier de l’OS. Les opérations ont toutes une complexité O(1), et il n’y a pas d’accès randomisé ce qui veut dire que les opérations de lecture/écriture sont parallélisables.
Kafka dans une architecture µ-service
Kafka est très adapté dans une architecture µ-service car il participe au :
-
Faible couplage: les µ-services qui produisent des messages n’ont aucune connaissance de ceux qui en consomment. Du coup, les deux peuvent évoluer indépendamment les uns des autres.
-
Techno-agnosticisme: tant que les langages de programmation utilisés implémentent leurs propres clients Kafka, vos µ-services peuvent s’échanger des messages.
-
Élasticité des communications: les communications via HTTP sont synchrones, ce qui veut dire qu’en période de montée en charge vos devez disposer d’assez de Serveurs/CPU/RAM pour recevoir le nombre de requêtes, et qui veut dire aussi qu’en période de faible charge, vous allez gaspiller ces même ressources pour rien. Kafka permet de traiter les requêtes sous forme de messages au fil de l’eau, du coup vous maîtrisez en amont la charge max (que vous pouvez changer dynamiquement) que peut recevoir vos clients.
-
Tolérance aux pannes: au cas où vous clients partent en cacahuètes, vous pouvez toujours rejouer les messages perdus tant que leurs périodes de rétention ne s’est pas écoulées.
Kafka pour .NET et Talend
-
La bibliothèque la plus utilisée pour .NET est confluent-kafka-dotnet, elle implémente toutes les fonctionnalités d’un client Kafka traditionnel. Elle est un wrapper sur le client Kafka natif C/C++ librdkafka, ce qui veut dire qu’elle est hyper-performante.
-
Talend dispose de plusieurs composants utiles:
-
tKafkaInput: transmet les messages Kafka à traiter dans le job.
-
tKafkaInputAvro : transmet les messages Kafka à traiter dans le job sous format Avro.
-
tKafkaOutput: publie des messages vers Kafka.
-
tKafkaCommit: sauvegarde l’état courant du tKafkaInput.
-
tKafkaConnection: ouvre une connection Kafka réutilisable.
-
tKafkaCreateTopic: permet de créer un topic Kafka.
-
Conclusion
Kafka est un système de messagerie performant, distribué, scalable et tolérant aux pannes. Il s’avère de ce fait très utile quand on fait du BigData sur Hadoop/Spark/Storm. Pas mal de mastodontes comme Spotify, Netflix, Uber, Goldman Sachs et Paypal l’utilisent pour traiter les données et comprendre les clients, leurs comportements, et les systèmes. Essayez le dès aujourd’hui.
Références
Badre BSAILA, Ingénieur d'étude et développement .NET sénior